The AI Model Landscape: A Moving Target
TLDR
For personal use, my favorites are Claude Sonnet 3.7, Grok 3, and Gemini 2.5 Pro. For development purposes, Gemini 2.0 Flash offers the best balance of cost, native capability, and speed, though OpenAI still provides the best overall development experience. The AI model landscape is evolving at a dizzying pace, with tech giants and startups alike pouring billions into research and infrastructure. What's "state-of-the-art" changes almost monthly, making any definitive ranking of models a snapshot that quickly becomes outdated. Nevertheless, understanding the relative strengths of today's leading models can help organizations make informed decisions about which technologies to adopt.
Understanding Model Evaluations
When comparing AI models, we often rely on benchmarks or "evals" that test specific capabilities. Common evaluation categories include:
- Reasoning: Logical problem-solving and deduction
- Knowledge: Factual recall and subject expertise
- Math: Numerical computation and mathematical reasoning
- Coding: Programming ability and technical understanding
- Safety: Resistance to harmful outputs or manipulation
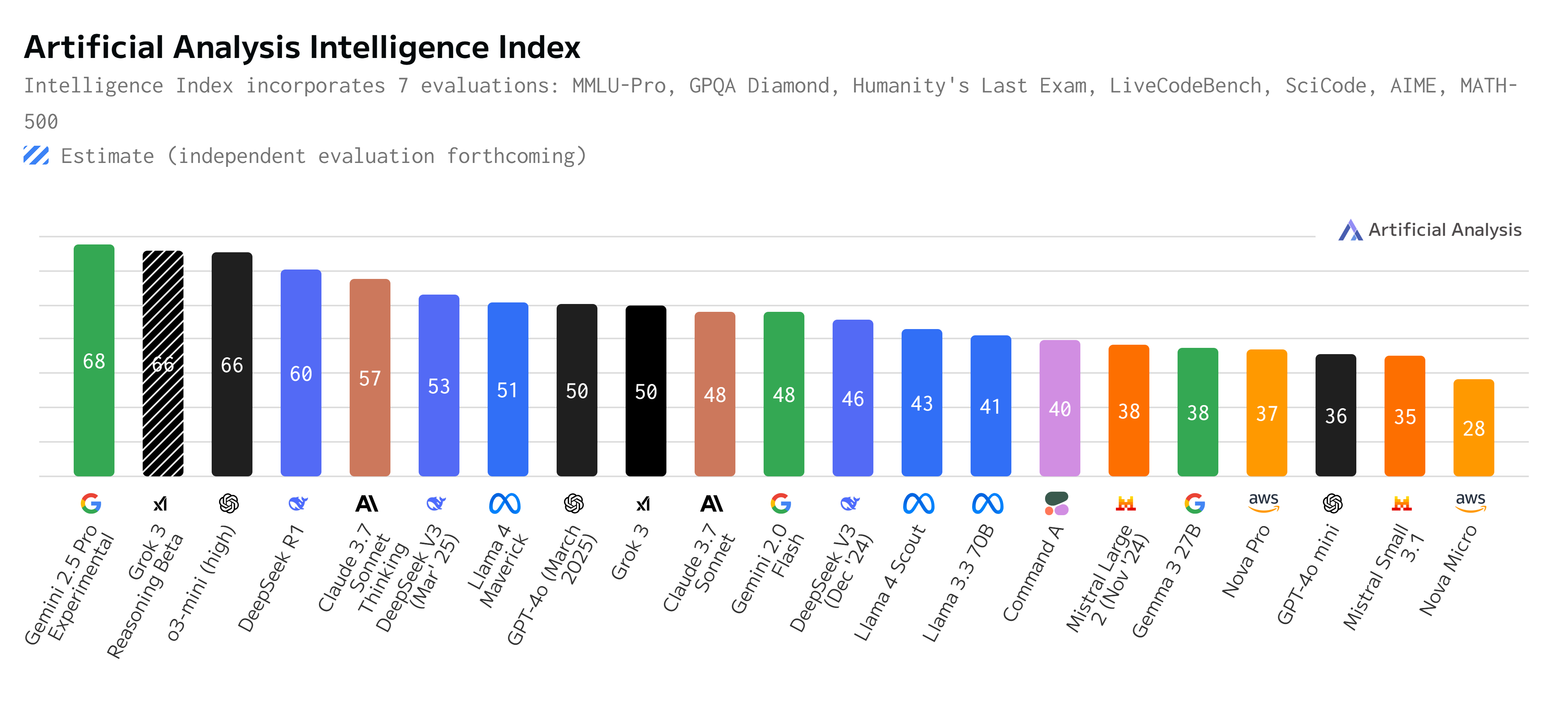
The table below summarizes how today's leading models compare across key metrics:
| Model | Provider | Intelligence | Speed (tokens/s) | Latency (s) | Price ($/M tokens) | Context Window |
|---|---|---|---|---|---|---|
| Gemini 2.5 Pro | 68 | 204.3 | 23.28 | 3.44 | 1M | |
| o3-mini (high) | OpenAI | 66 | 214.1 | 37.97 | 1.93 | 200k |
| o3-mini | OpenAI | 63 | 186.1 | 11.97 | 1.93 | 200k |
| o1 | OpenAI | 62 | 71.6 | 37.38 | 26.25 | 200k |
| Llama 4 Scout | Meta | 43 | 137.0 | 0.33 | 0.23 | 10M |
| Nova Micro | Amazon | 28 | 319.5 | 0.29 | 0.06 | 130k |
| DeepSeek R1* QWEN 1.5B | DeepSeek | 19 | 387.1 | 0.24 | 0.18 | 128k |
| DeepSeek R1* QWEN 32B | DeepSeek | 52 | 43 | 0.3 | 0.3 | 128k |
However, there's often a disconnect between benchmark scores and real-world performance. A model that excels in controlled evaluations might underperform in practical applications for several reasons:
- Benchmark tasks may not reflect actual use cases
- Context length limitations affect complex tasks
- System prompts and fine-tuning dramatically impact performance
- Real-world use involves messy, ambiguous inputs
This is why many organizations find that hands-on testing with their specific use cases provides more valuable insights than published benchmark scores alone.
The Major Players and Their Strengths
Based on current benchmarks from artificialanalysis.ai as of April 2025, here's where the leading models stand out:
Gemini 2.5 Pro Experimental (Google)
- Intelligence score: 68 (highest among current models)
- Output speed: 204.3 tokens/second
- Context window: 1 million tokens
- Best for: Complex reasoning tasks, vision-related applications, and handling lengthy documents
- Limitations: Higher latency (23.28s) and cost ($3.44 per million tokens)
o3-mini (OpenAI)
- Intelligence score: 63-66 (depending on variant)
- Output speed: 186.1-214.1 tokens/second
- Price: $1.93 per million tokens
- Best for: Cost-effective text generation that maintains high intelligence
- Limitations: 200k token context window, which is smaller than some competitors
DeepSeek R1 Distill Qwen 1.5B (DeepSeek)
- Output speed: 387.1 tokens/second (fastest available)
- Latency: 0.24s (extremely low)
- Price: $0.18 per million tokens (very economical)
- Best for: Real-time applications like chatbots requiring immediate responses
- Limitations: Lower intelligence score (19) compared to premium models
Llama 4 Scout (Meta)
- Context window: 10 million tokens (largest available, uhhmmm "allegedly" )
- Intelligence score: 43 (solid middle-tier performance)
- Price: $0.23 per million tokens (cost-effective)
- Best for: Processing extremely long documents or extended conversations
- Limitations: Moderate output speed (137 tokens/second)
Nova Micro (Amazon)
- Output speed: 319.5 tokens/second (very fast)
- Price: $0.06 per million tokens (extremely economical)
- Best for: High-speed, budget-conscious applications
- Limitations: Lower intelligence score (28) for complex reasoning tasks
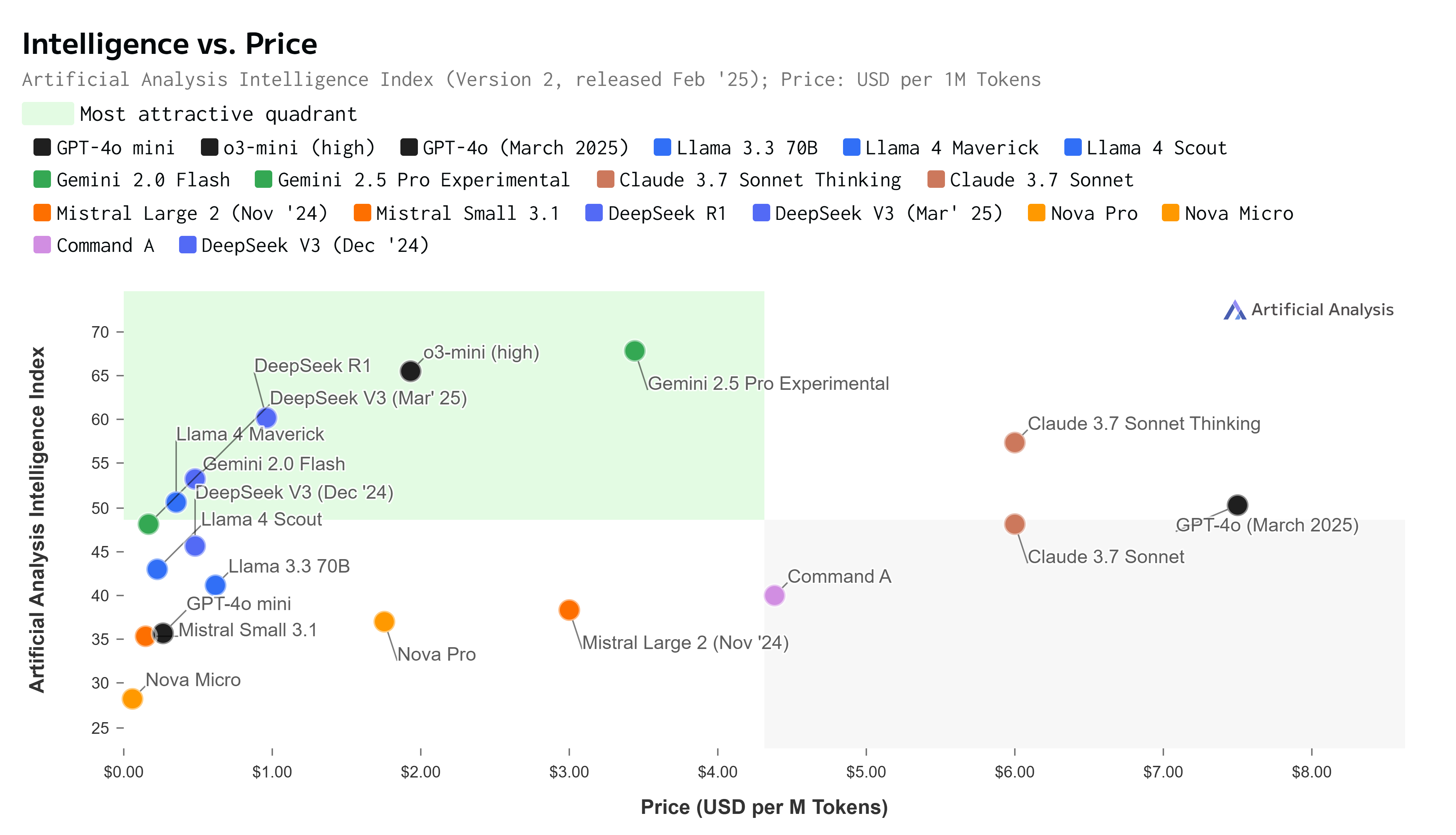
Specialized vs. General Models
While much attention focuses on general-purpose models, specialized models often outperform them in specific domains:
- Code models like DeepSeek Coder and Anthropic's Claude for coding excel specifically at programming tasks
- Mathematical models such as Google's AlphaGeometry show superhuman performance in narrow domains
- Scientific models like Meta's Galactica or ESMFold are optimized for specific research fields
Organizations often find that combining general models for broad tasks with specialized models for specific functions yields the best results.
The Benchmark vs. Reality Gap
Evaluating benchmark scores from sites like artificialanalysis.ai provides valuable comparative data, but these metrics should be interpreted with caution. Some important considerations:
- Prompt sensitivity: Minor changes in how questions are phrased can dramatically affect performance
- Version volatility: Models are frequently updated, sometimes with regression in certain capabilities
- Context matters: Real-world applications often require understanding nuance and context that benchmarks don't capture
- Integration factors: How models integrate with existing systems can be more important than raw performance
Many organizations report that models ranking lower on certain benchmarks actually perform better for their specific use cases due to these factors.
Navigating the Shifting Landscape
Given the rapid pace of development, organizations should consider:
- Testing multiple models directly against your specific use cases
- Regularly re-evaluating as new versions are released
- Focusing on business outcomes rather than benchmark scores
- Building adaptable infrastructure that can switch between models as the landscape evolves
The most effective approach is often to run pilot projects with several models to assess their performance in your specific context. For example, while DeepSeek R1's speed makes it appealing for real-time applications, its lower intelligence score might be insufficient for complex tasks where Gemini 2.5 Pro would be more suitable despite its higher cost and latency.
For most organizations, the "best" model isn't necessarily the one with the highest benchmark scores, but the one that best fits their particular requirements, technical infrastructure, and budget constraints. This might mean using different models for different functions – perhaps Gemini 2.5 Pro for complex reasoning tasks and DeepSeek R1 for customer-facing chatbots.